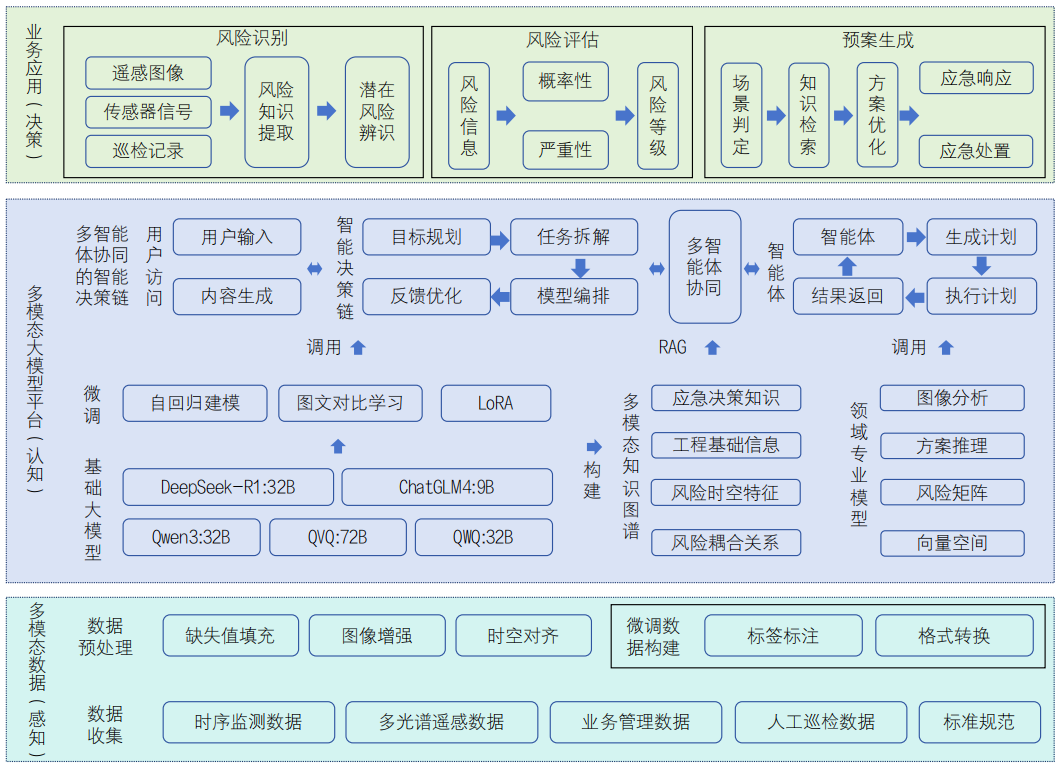
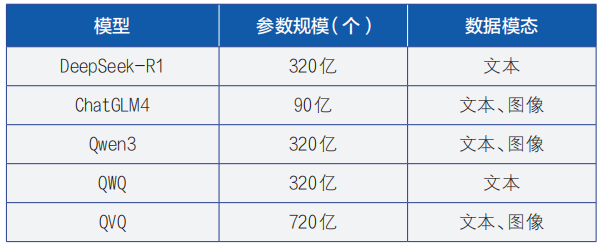
胡春宏:数字孪生流域模型研发若干问题思考
一、数字孪生的由来与内涵
数字孪生思想早在20世纪60年代已出现,当时美国国家航空航天局在太空探索任务中率先使用了数字孪生技术,每个航天器都被精确地复制成相同模型,供科研人员用于研究和模拟。1991年耶鲁大学教授大卫·盖勒特首次提出了数字孪生概念。2002年密歇根大学教授迈克尔·格里夫斯首次将数字孪生概念应用于制造业,并正式宣布了数字孪生的软件概念。2010年数字孪生这一术语被美国国家航空航天局正式提出。
数字孪生又称“数字双胞胎”,学术界和产业界对此有不同的定义,但通常可以理解为:以数字化的方式建立物理实体的虚拟模型,再通过实时数据和算法模型实现物理实体和虚拟实体的映射和交互,实现对物理实体状态变化趋势的科学预测和改善优化,具有互操作、可扩展、高保真、实时和闭环等特性。从定义看,数字孪生表现出物理实体、虚拟实体及二者连接的三维架构特点,其本质就是要构建一个物理实体的虚拟孪生体, 其核心要素是数据、模型、映射和交互。
二、数字孪生流域面临的挑战与思考
近年水利部提出智慧水利建设,即以数字化、网络化、智能化为主线,以数字化场景、智慧化模拟、精准化决策为路径,以构建数字孪生流域为核心,全面推进算据、算法、算力建设,加快构建具有“四预”功能智慧水利体系。
然而要真正实现数字孪生流域,目前还面临不少挑战。数字孪生流域是以物理流域数据为底座、专业数学模型为核心、水利知识为驱动,对物理流域全要素和水利治理管理活动全过程的数字化映射、智能化模拟,实现与物理流域同步仿真运行、虚实交互、迭代优化。
鉴于数字孪生具有物理实体、虚拟实体及二者连接的三维架构特点,数字孪生流域可概括为三个层级(三个过程),即第一层级L1,包括物理流域信息数据化和气象降水预报,这是两个独立事件,属于数据底板层,其中流域信息包括地形、土壤类型、植被状况、河流湖泊水库、水利工程等众多信息集总并动态及时更新;第二层级L2,是基于第一层级L1进行的流域产汇流模拟;第三层级L3,是以第一层级L1和第二层级L2为初始和边界条件,开展土壤侵蚀、洪水预报、泥沙输移、地下水等专业模型模拟,属于直接应用层。
如果把虚拟实体与物理实体的相似程度称为保真度,那么数字孪生流域整体保真度必然与每一个独立事件保真度有关。对于专业模型来说,保真度就是模型计算精度。需要说明的是,保真度为0代表完全失真,保真度为1代表100%保真。从目前技术水平来看,数字孪生流域中每一个独立事件的保真度都难以达到100%,因此随着层级增加,保真度必然逐级衰减。
(关于保真度的计算,请参见原文)
假定每个独立事件的保真度为0.9,可计算得到L1的综合保真度是0.86,L2和L3的保真度分别为0.83和0.80(见表1)。

从表1可以看出,如果独立事件的保真度只有0.80,那么到应用层L3保真度只有0.60,对实际应用有一定的参考意义。如果独立事件的保真度达到0.90,这已经是目前水利专业模型所能达到的较高水平了,那么到应用层L3保真度能达到0.80,虽对实际应用具有一定的指导意义,但离数字孪生流域高保真的要求还有一定距离。由此可见,要真正建成高保真的数字孪生流域还面临很多挑战,当务之急是提高数字孪生流域建设中各层级的保真度和精度。
为了提高数字孪生流域保真度,建议采用以下两条路径。
路径1:主要是提高每一个独立事件的保真度,从而提高数字孪生流域整体保真度。这就要求在实际工作中针对算据必须从技术上解决流域信息数字化的高保真问题,切实提高物理流域信息的感知能力,动态更新流域信息,保证数据底板信息准确实时;同时在算力和算法方面要继续深化降水、产汇流、土壤侵蚀、泥沙输移、洪水演进等物理过程机理研究,优化核心算法,提高计算效率,不断改善专业模型模拟精度,使模拟结果逐渐逼近真实物理过程。理想状态下,假定每个独立事件的保真度提高到0.95,计算得到应用层L3的保真度为0.90,对实际应用具有较大指导意义,但尚达不到数字孪生流域高保真的要求。这也是数字孪生流域建设遇到的实际问题。
路径2:在路径1基础上,直接跳过某些层级,通过减少过程中保真度损失,提高整体保真度。比如可以跳过降水预报甚至产汇流模拟这两个环节,作为替代采用高精度的信息感知技术,实时监测给出河流断面的流量和含沙量过程,直接供洪水预报和泥沙输移等模型调用。在该路径下,如果每个独立事件的保真度能提高到0.95,河流流量和含沙量监测精度也按0.95考虑,由于跳过了某些中间环节,计算得到应用层L3的保真度为0.91,对实际应用具有很大指导意义。
需要说明的是,独立事件的保真度达到0.95已经是非常理想的状态,在如此理想条件下应用层L3的保真度也只有0.91,也就说明在现实中要实现数字孪生流域100%的保真度是非常困难的。这样的判断对于数字孪生流域的认识以及建设的目标、建设的方向等具有一定的参考价值:即建设数字孪生流域需要较长时间,不必追求100%保真。事实上,由于流域信息复杂多样,在数字化过程难以像工业产品那样做到100%保真,加之水利专业模型本身的物理机理还不成熟,其模拟结果必然与物理实体存在差别,这两方面原因决定了数字孪生流域的保真度难以达到100%。
从以上两条路径可以看出,无论哪条路径,提高第一层级物理流域信息数据化的保真度和第三层级专业模型的计算精度都是必须的。流域信息数据化保真度的提高依赖于电子、信息、计算机、人工智能、仪器设备等多个专业的技术进步和技术融合,限于篇幅这里不加论述。鉴于大部分专业模型位于第三层级,也是数字孪生流域建设的核心,因此如何提高模型的精度成为改善数字孪生流域保真度的关键一环。下面以已经列为水利部重大科技项目的泥沙通用数学模型和土壤侵蚀模型为例,具体分析阐述如何开展水利专业模型研发,以提高数字孪生流域整体保真度、支撑数字孪生流域建设。
三、泥沙通用数学模型研发
泥沙数学模型作为数字孪生流域的核心模型之一,为江河湖库保护与治理的各个环节提供边界条件,广泛应用于水库淤积计算、河道河口海岸冲淤演变预测、涉水工程泥沙问题模拟等工作,可为流域水沙调控、水库调度运用和河道河口海岸治理与保护提供量化的科学依据。
现有研究表明,不同河流的泥沙运动和河床演变均遵守同样的理论和物理规律,也就是说泥沙基本理论与方程适用于所有河流,只是对不同河流其中的参数和系数取值有所不同,研发泥沙通用数学模型的条件已经具备。
我国泥沙研究总体上处于国际领先水平,泥沙数学模型有很好基础,已经广泛应用于河道治理、水库泥沙调度运用、涉水工程泥沙问题解决,其可靠性已经被大量实践所检验。然而目前国内泥沙数学模型依然存在一些问题:一是泥沙数学模型小散乱现象突出,精度良莠不齐,通用性不强;二是模型前后处理还没有完全实现标准化和可视化,软件化程度低;三是一些特殊水沙运动数学模型还有待完善,比如堰塞湖溃决过程模拟、山区河流洪水过程模拟等。因此迫切需要升级完善现有泥沙数学模型提高模拟精度,提高数字孪生流域整体保真度。在未来一段时间里应着重做好以下研发工作。
1.机理研究方面
主要是改进算法提高精度。继续深化非均匀悬移质不平衡输沙理论研究、宽级配推移质不平衡输沙机理研究,水流挟沙能力通用性研究,长历时低含沙水流作用下床沙交换机理和河床粗化机理研究,山区中小河流山洪大冲大淤机理研究。特别要开展山区河流高坝大库下游河床冲刷机理研究,包括宽级配泥沙分选、粗细沙交换、冲刷粗化、交换粗化、大级配覆盖层破坏、以及再造床等多过程,为提高泥沙数学模型模拟精度提供理论基础。
2.软件开发方面
主要是提升算力,减少数据处理对精度影响,实现标准化和可视化。
一是优化泥沙通用数学模型求解器,保证挟沙能力公式相对通用和参数取值有理有据,避免参数选择的不确定性,使得一个泥沙数学模型能适用于所有河流和水库。
二是基于地理信息技术,研发水沙数学模型的数据管理功能,实现对水文、泥沙、水下地形的按需调取,自动形成模型计算输入数据,模拟成果的存储、查询、更新和删除等功能。
三是基于地理信息系统平台,研发模型前处理功能模块,实现水沙与地形条件准备、参数设定和计算方案存储与调取功能;基于虚拟现实,研发模型后处理功能模块,实现水位、流场、含沙量场、冲淤分布等信息的可视化,以及泥沙模型在不同数字孪生场景和不同业务应用之间的调用。
3.特殊水沙运动模拟技术方面
主要是提高模拟精度、增加模型功能和应用场景。目前在堰塞湖溃决、山洪大冲大淤的极端泥沙运动模拟方面还存在明显短板。
一要开展堰塞湖溃决过程的数值模拟研究,研发具有明确物理机理和模式的数值模拟技术,在不引入假定和不确定性参数条件下,实现对堰塞湖溃决过程和流量过程的快速精确模拟,给出最大洪峰流量及出现时刻,直接用于堰塞湖应急除险决策。
二要开展基于动床的山区河流洪水过程模拟研究,山洪具有大冲大淤特点,目前普遍采用定床模型计算精度差,亟待研发水—沙—床耦合作用下的山洪流量过程和水位过程的数学模型,解决因河床大幅冲淤导致山洪流量和水位测不准、算不精的难题,提高中小河流山洪灾害预报精度和防御能力。
在以上研发工作基础上,再从模型理论基础、待定参数、计算精度、实际工程检验、通用性和稳定性等六个维度对现有泥沙数学模型开展系统的评价工作,甄选出真正具有高精度的泥沙通用数学模型,形成集标准化和可视化于一体的泥沙通用数学模型软件,以提高数字孪生流域整体保真度。
四、分区分类土壤侵蚀模型研发
土壤侵蚀模型是数字孪生流域核心专业模型之一,是智慧水土保持建设的核心内容,是评价水土流失状况、变化、影响及其防治成效的必要手段。由于我国相关研究起步晚、成果分散和投入不足等现实原因,现有土壤侵蚀模型还不能满足新时期水土保持高质量发展需要,不足以支撑现代智慧水利发展要求。为推进数字孪生流域建设,迫切需要开展土壤侵蚀模型研究工作。
同时由于我国水土流失分布广、不同类型区的土壤侵蚀机理差别大,既有以水力、风力、冻融和重力等侵蚀营力为主的水土流失区也存在许多复合营力耦合作用的水土流失类型,因此难以采用一套全国尺度的通用模型来满足不同区域和不同需求的应用。为此,按照不同水土流失区域和类型的侵蚀机理,采用分区分类研发土壤侵蚀模型更切实际,有利于提高数字孪生流域整体保真度。近期应重点开展如下方面模型研发工作。
1.西北黄土高原区土壤侵蚀模型
应以大糙率、小水深的薄层水流挟沙动力机制为核心,针对年际、年内和次降雨等不同时间尺度下,坡面、沟道、流域的泥沙产输全过程,构建基于侵蚀动力方程的分布式侵蚀产沙机理模型。除水力侵蚀外,还应考虑沟坡局部偶发的重力侵蚀过程以及淤地坝拦沙减蚀影响。
2.东北黑土区土壤侵蚀模型
应以长缓地形和人为垄作影响下农田水力侵蚀过程为核心,研究黑土区坡面土壤侵蚀模型,并以农田浅沟和切沟为重点,基于沟蚀发育演化的动力过程,研究东北黑土区侵蚀沟土壤侵蚀模型,最终耦合构建包含面蚀和沟蚀的东北黑土区土壤侵蚀机理模型。
3.北方风沙区土壤侵蚀模型
应针对北方典型风蚀和风水交错侵蚀区域,以风沙启动、运移、沉积动力机制为核心,研究风力侵蚀、风水复合侵蚀发生机理与过程,确定并率定土壤侵蚀关键影响因子,构建包含风蚀和风水交互侵蚀的北方风沙区土壤侵蚀机理模型。
4.南方红壤区土壤侵蚀模型
应以崩岗的复合营力侵蚀过程为重点,研究其分布和发生规律,解析其发育演变的动力机制,构建预警预报模型,并与坡面、沟道和流域水力侵蚀过程耦合,构建南方红壤区土壤侵蚀机理模型。
除上述具备较好研究基础区域外,未来还应逐步加强西南岩溶区土石二元地表与岩溶地质导致的土壤流失与漏失过程及预报、青藏高原区冻融作用下土壤侵蚀过程与预报,同时针对水土保持管理需求同步研发生产建设项目人为水土流失风险预警模型、小流域水土流失综合治理智能管理模型等相关应用模型。逐步形成分区分类全国土壤侵蚀模型体系。这有利于提高数字孪生流域整体保真度,也可加快为数字孪生流域建设和新时期水土保持高质量发展提供科技支撑。
五、结语
基于数字孪生具有物理实体、虚拟实体及二者连接的三维架构特点,分析了数字孪生流域中独立事件保真度及其在层级间的衰减。提出在目前技术水平下,数字孪生流域的保真度一般在0.80左右,虽然对实际应用具有一定的指导意义,但离数字孪生流域高保真的要求尚有一定距离,当务之急是提高数字孪生流域建设中各层级的保真度和精度。
提出了提高数字孪生流域保真度的两条路径,对于第二条路径,在理想状态下,假定独立事件的保真度达到0.95,数字孪生流域整体保真度可达0.91,对实际应用具有很大指导意义,但要实现数字孪生流域100%的保真度非常困难。这样的判断对于数字孪生流域的认识以及建设目标、建设方向等具有一定的参考价值:一是建设数字孪生流域需要较长时间,不必追求100%保真;二是进一步提升物理流域信息数字化技术水平和加强核心专业模型研发是非常必要的。
最后以泥沙数学模型和土壤侵蚀模型为例,提出了模型研发的方向。