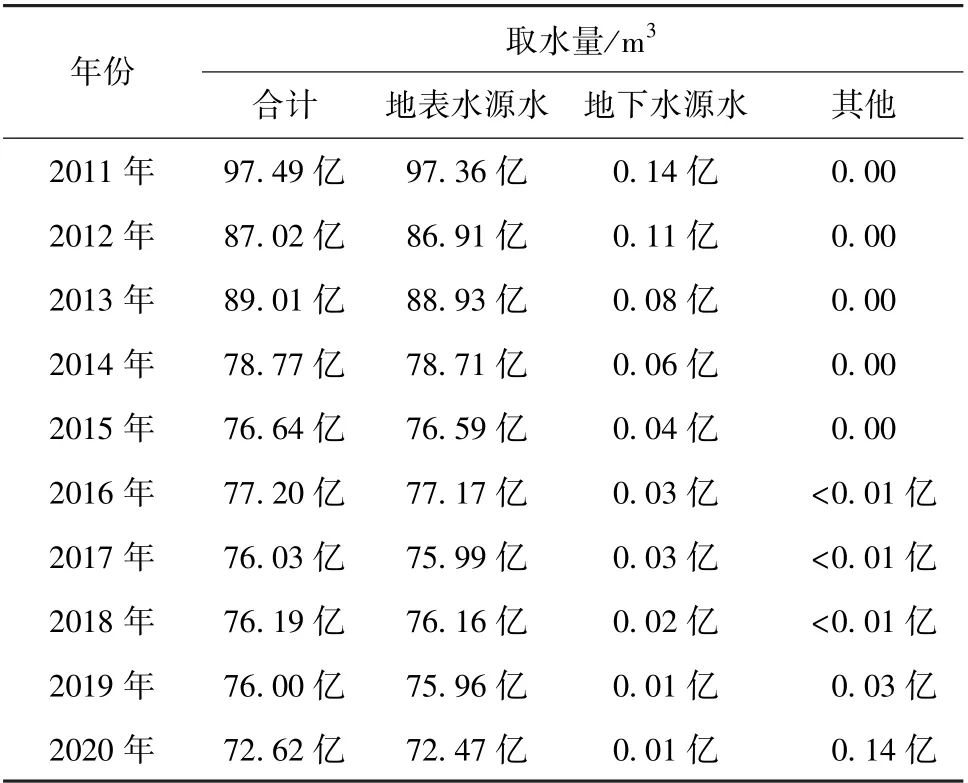
机器学习方法在污水处理系统中的应用
研究背景
近年来,随着我国对水污染治理的投入持续增加,水处理技术的发展和废水处理设施规模的增大,处理工艺变得越来越复杂;此外,由于污水的水质水量波动较大,受外部干扰较多,污水处理系统(尤其是生物处理系统)具有耦合性强、滞后性大等特点,系统中各个部分之间彼此关联,一个条件的改变可能影响整个系统,具有很强的不确定性。而传统手段,如依靠经验或者是简单的控制系统已经不能满足当前污水处理系统的需求,导致污水处理设施建设和运行过程中存在的运行质量差、处理效率低和资源利用率低等问题,并受到了越来越多的关注。
传感器及在线监测设备在污水处理系统的使用日益频繁,也为工程技术人员采集了大量的数据,如水温、pH、浊度、流量、化学需氧量(COD)、生物需氧量(BOD)、色度等,结合物联网技术的应用,这些数据被存储在本地计算机或上传至云服务器,为污水处理系统预警、调控和故障诊断提供了基础信息。物联网系统持续的数据采集会产生大数据,如何分析这些数据并从中提取关键信息用于污水处理系统的调控是目前的研究热点。
机器学习方法可充分利用大数据进行非线性回归、分类和预测、诊断异常数据点以及为多目标系统寻找最优决策方式,是近年来解决复杂工程系统问题的重要手段之一。同时,机器学习方法容错率高,可适应较大的输入数据变化,能很好地利用污水处理过程中产生的数据集,并可通过不断优化达到较好的学习效果。正因为具有以上这些特点,近年来在污水处理领域,已有很多科研人员将机器学习方法应用于解决复杂的实际工程问题,并且在解决污水处理过程中水质预测准确率低、故障诊断困难以及调控滞后方面取得了一系列进展。本文将围绕近年来机器学习在污水处理领域的应用展开讨论和分析,以期为相关领域的科研人员和工程技术人员提供了借鉴。
摘要
由于污水处理系统一般较为复杂且受外界因素影响较多,对其进行精准调控一直是环境领域的难题之一。传统方法无法满足日益复杂的工程项目需求。近年来发展起来的机器学习方法为此类问题提供了一系列有效的解决方案。介绍了人工神经网络、支持向量机、随机森林等机器学习方法的特点,并从水质预测预警、污水处理系统故障诊断和智能控制3个方面阐述了机器学习方法在污水处理领域的应用,分析了机器学习方法相较于传统方法的优势及其应用于污水处理系统中存在的问题,展望了机器学习方法未来在污水处理领域应用的前景和趋势。
01、机器学习方法分类及简介
机器学习方法主要是利用选定的模型对输入数据进行学习,从复杂的数据集中提取出有价值的特征或信息,归纳出合理的变化趋势,从而进行数据预测,是一种可以在比较预测值与实际值偏差后,重新调整模型中参数或者结构以提高预测的准确性和可靠性的方法。根据模型对输入数据的标记方式不同,机器学习可分为监督学习、无监督学习及半监督学习等类别。
1. 监督学习
监督学习是机器学习方法的重要分支之一,主要应用于对已知类别的数据集进行学习训练,通过计算模型寻找数据特征和类别之间的关系,并根据训练结果进行预测。监督学习是目前在各个领域应用较为广泛的一种机器学习方法,主要包括线性回归(linear regression)、支持向量机(support vector machine,SVM)、贝叶斯分类(bayesian classifier,BC)、人工神经网络(artificial neural network,ANN)、随机森林(random forest,RF)以及逻辑回归(logistic regression)等算法。其中,线性回归和逻辑回归等回归算法主要是用于研究简单的自变量和因变量之间的关系,但由于污水处理过程十分复杂,常规的回归计算不能满足系统预测预警及监控要求,相比之下,SVM和ANN更适合解决此类复杂问题。SVM常用于分类,其实质就是将样本数据以向量形式投射到1个更高维的空间中,并建立1个超平面,目的就是为了能够找到1个超平面,该超平面到所有样本最小,此方法能够最小化经验误差和模型复杂度,以提高分类效果或者是解决一般化的回归问题,但是SVM仅适用于处理小规模数据,如果样本量过大,会使得计算过程过于复杂而不能保证分类的准确性;ANN算法则是将输入信号以激活函数的形式从一个神经元传递到另一个神经元,在激活函数中输入信号数值,经过一定的非线性计算后输入下一层,直至输出结果,常见的激活函数有Sigmoid、Tanh、ReLU和ELU函数等。这2类机器学习算法被广泛应用于环境预测的相关领域,涉及环境生态学、水处理以及关于水质量监测的数据建模等方面(图1)。

图1 机器学习方法的分类及其在污水处理系统中的应用
2. 无监督学习
无监督学习则是机器学习方法的另一重要类别,与监督学习方法不同,无监督学习主要用于分析未分类的数据,从数据集中提取出潜在关系或者特征,进而将其分组成簇。目前主流的无监督学习算法主要包括主成分分析(principal components analysis,PCA)、K均值聚类(K-means clustering)、卷积神经网络(convolutional neural network,CNN)和自组织映射(self-organizing map,SOM)等。其中,PCA和K均值聚类是2种最基础的无监督学习方法,PCA被广泛用于数据降维,它可以从高维数据中提取低维子空间并尽可能保留数据的多样性,具体做法是将高维(n维)特征映射到低维(k维)上,k维即是全新的正交特征,也被称为主成分,是在原有n维特征的基础上重新构造出的k维特征,因此适用于处理复杂多维度的污水工艺问题,但由于其自适应能力差,对水质水量变化较大的污水工程实用性不强;K均值聚类算法是一种常用的聚类算法,通过迭代将给定的数据对象划分为k个不同的聚类并收敛到局部最小,以完成聚类的过程,该方法运行速度快,并且适用于处理大型数据集,但是由于算法输出依赖于随机种子(k值和聚类中心的选择均依赖于随机种子),需要进行反复运算以优化k值及聚类中心。在污水处理中,K均值聚类方法可用于检测系统故障,具体见图1。
3. 其他机器学习方法
除了监督学习和无监督学习以外,还有一些其他类型的算法,如可根据少量标记数据而进行学习的半监督学习算法以及在线建立模型的强化学习算法等。前者可以仅依靠少量标记数据及大量未标注数据进行学习,训练模型已应用在实际工程中;后者则是利用变化的环境状态传递给系统的信息来判断该变化是否带来相应的收益,并将该变化与收益存储,然后不断寻求能够取得最大收益的下一个决策。其中比较典型的是Q学习(Q-learning)算法,通过构建1张Q表格来存储系统中的环境变量以及该变量所能够带来的收益,然后根据该Q表格来选取能够获得最大收益的动作。在污水处理领域,Q学习算法可用于优化反应器水力停留时间(HRT)。
02、机器学习在水质监测和预警中的应用
机器学习在污水处理系统中的应用实例见表1。
表1 机器学习在污水处理系统中的应用实例

1. 机器学习应用于水质监测及预警的优势
机器学习方法应用过程中需要大量数据对模型进行训练以模拟问题过程。随着众多新型传感器、物联网、云计算、监视控制和数据采集系统(SCADA)等技术在污水处理系统中的广泛应用,水温、pH、浊度、流量、COD、BOD、色度、DO、水位等数据大量、持续产生,为机器学习在污水处理领域的应用提供基础。基于这些庞大的数据集,机器学习可从中寻找规律,并根据历史记录有效预测未来的发展趋势,从而应用于污水处理的监测和预警中,以了解污水处理过程的实时状态,也能及时预测未来出水水质、处理效果及可能会发生的故障等。
采用机器学习进行污水处理监测和预测有着诸多优点,如机器学习可以对非线性问题做出较好的预测。而污水处理系统是一个包括生化和物化反应极其复杂的过程,且水质水量波动较大,因此具有较大的不确定性、耦合性和滞后性。常规的人工经验判断或者一般的数学模型不能全面描述这样的复杂过程,而机器学习拥有较高的鲁棒性、可靠性和泛化能力,能够较好地应对这些问题。
另外,机器学习可以同时对多组数据进行关联。相较于传统的在线监测系统中只对单个监测点进行记录而不涉及任何多变量计算,利用机器学习对污水处理进行监测时可将多个时间点的多个数据进行关联处理,从而更清晰地了解污水处理过程中污水状态的一般性质,实时掌握污水处理系统的运行状态,避免各类风险及故障。
2. 机器学习在水质监测和预警领域的应用方式
在具体的污水监测工作中,目前尚无通用模型,因此需要根据不同的情况选择合适的计算模型。目前在污水监测领域使用较多的机器学习模型包括SVM、ANN、ANFIS、DNN、RT和人工神经网络-遗传算法的混合模型等几种类型,主要用于预测污水中的TN、BOD、COD、总悬浮固体(TSS)和总溶解性固体(TDS)浓度,以及污水处理反应器中的污泥膨胀系数等,并且根据预测结果对可能发生的异常情况进行预警。
ANN和SVM是目前在污水预测领域使用最多的机器学习模型(表1),这2种模型都需要有大量历史数据作为基础,并且仍然有着较大的改进空间。在美国社区污水源的预测案例中,研究人员发现使用SVM模型时存在预测值低于实际值的情况,且变量过少可能导致模型性能降低。此外,多哈西部污水厂、韩国蔚山污水厂采用ANN及SVM模型对污水进行预测,均未达到预期。针对这一问题,多哈西部污水厂使用相关矩阵和Levenberg-Marquardt算法进行了相关性分析和参数优化,韩国蔚山污水厂则利用latin-hypercube one-factor-at-a-time及搜索算法进行了敏感性分析和模型参数优化,两者均取得良好的预测性能,并且建立了图形用户界面以供使用,在一定程度上实现了异常水质的预报预警。
除了经典的ANN和SVM算法外,在尼克西亚的污水厂中,研究人员使用由ANN衍生的前馈神经网络(FFNN)和自适应神经模糊推理系统(ANFIS)对污水厂出水的COD、BOD和TN进行预测,发现ANFIS方法相比于其他模型有着更好的预测效果,而将几种机器学习模型进行组合并综合预测,会比使用单一方法的预测准确率提高24%。
机器学习方法不仅可用于水质监测和预测领域,还可用于污水处理的其他方面,如活性污泥状态监控。目前,ANN已被用于活性污泥反应过程的监测、分类和控制,其中自组织径向神经网络可有效预测污泥膨胀系数。在此基础上,Bagheri等在Ekbatan污水处理厂,使用经过遗传算法(GA)优化的混合多层感知器人工神经网络(MLPANNs)和径向基数人工神经网络(RBFANN)模型,可准确预测污泥膨胀系数(平均误差不超过输入值的3%)。
总之,机器学习在污水处理系统监测和预警领域有着广泛应用,但由于污水处理本身非常复杂,环境条件及处理工艺各不相同,针对不同的工艺应尝试多种机器模型算法,以寻求最佳的监测及预测效果。
03、机器学习在污水处理中系统故障诊断中的应用
1. 污水处理过程中的故障诊断
传统的故障诊断方法众多,基于历史数据(定量数据、定性数据和过程数据)的故障诊断方法一般仅适用于简单或线性的机械问题,在应对高维度、非线性的污水处理问题时,传统的故障诊断方法较注重微观结构、强调及时变化的特点,无法全面描述复杂系统的变化规律。
采用机器学习对污水处理设施进行故障诊断可转化为基于历史数据对状态进行分类的问题。典型的监督学习方法(如SVM、ANN、贝叶斯网络等)可将故障诊断问题从二元分类问题扩展为多类别分类问题,以达到较为可靠的故障检测效果。同时在无监督学习中,如K均值聚类、PCA和期望最大化聚类方法中,可将异常问题判定为单独聚类或是远离正常簇的点位,从而达到故障诊断的效果。
机器学习方法基于庞大的数据库,对系统进行持续监测和预测,从而发现问题并有效地实现远程和本地维护。当采用机器学习方法进行故障诊断时,不需要关注污水处理中每一部分的运行方式以及其中涉及的各类生化反应过程,而是对整个系统水质指标、运行状态、环境因素等数据进行采集和处理,从全局的角度进行监控和诊断,有效弥补传统方法在污水处理故障诊断方面的缺陷。其基本原理是将当前各类监测数据或系统状态与之前积累的正常或非正常历史数据进行比对,通过分类或聚类的方法,寻找当前数据与历史数据的相似之处,分析固有背景的变化与异常,及时诊断污水处理系统运行情况的正常与否。因此,机器学习需要收集大量的原始数据,结合适当的数据分析技术,将这些数据转化为有价值的信息,基于这些信息做出积极的决策,以优化总体性能。
2. 机器学习在污水故障诊断和预警领域的应用
机器学习方法在污水处理系统的故障诊断和预警方面的应用主要包括及时发现传感器失灵、突发水污染、管道泄漏以及系统运行参数大幅度波动等多种故障问题(表1)。
在农村社区污水处理厂和序批式活性污泥法(SBR)中试装置的应用实例中,研究人员以训练集作为基础,使用交叉验证的方式确定了若干主成分,前者利用PCA模型进行故障原因分析,后者则是通过分类判别溶解氧传感器或液位传感器故障,均获得了适用于工程应用的故障诊断效果,但这种多元统计方法需假设水处理过程中环境条件不发生明显改变,因此后者只适用于水质变化不大的情况。
针对上文提及的PCA模型不能应对环境条件变化的问题,一些自适应模型开始受到关注。肖红军等使用变分贝叶斯混合因子分析法对传统PCA的参数进行加权平均改进,使其可以针对污水处理系统中的实时变化自行修改,从而提高了该模型的预测预警能力。而在卢布尔雅那污水处理厂实例中,研究人员使用演化模糊模型来模拟各变量间的非线性关系,及时调整本地模型和服务器集群的参数并建立新的在线模型,来适应故障预警中的不同工艺条件。此外,另一类较为典型的自适应模型是基于自组织映射的神经网络,芬兰造纸厂污水处理系统和某污水厂BMS1仿真系统是自适应模型应用的典型案例(表1),前者利用基于SOM的监测系统,对活性污泥处理厂的工艺数据进行测试,后者利用帝国竞争算法对SOM神经网络进行优化,从样本中提取特征并根据特征聚类,解决了以往基于单一时刻使用有限数据来评价水处理过程状态的困难,为有效诊断工业废水处理过程中的故障提供了新的可能。
此外,随着机器学习技术的不断发展,越来越多的研究人员发现单一的机器学习模型无法较好地分析整个污水处理流程。如仅使用SVM对污水处理厂进行故障诊断会导致错误率较高,达到30%左右。而污水处理系统一旦发生误诊,可能会造成较大的损失,因此一些混合机器学习模型被应用到污水处理故障诊断领域,如可以整合改进的遗传算法和K均值聚类算法对污水厂的历史数据进行分析,建立污水厂工艺故障诊断规则,从而利用机器学习完成污水厂故障诊断及预警。在长沙第二污水处理中心的应用实例中,采用多类SVM,并使用GA算法对SVM进行优化计算,经过160多代的优化和演进,在关键类上的错分率可降低至2.9%,基本满足了在污水处理系统中故障诊断的要求。
由于污水处理过程中可能会发生的故障多种多样,且这些问题极有可能共同存在于同一个污水处理工程中,因此在寻求机器学习进行故障诊断时,单一的机器学习算法无法达到较好的效果。结合上文分析可以看出,采用多种算法混合机器学习方法对故障问题进行诊断和预测有望成为未来技术发展的主流趋势。
04、机器学习在污水处理系统智能控制中的应用
1. 传统控制方法和机器学习控制方法的比较
在污水处理过程中,一方面需要高效去除污染物,另一方面需要在水质达标的前提下节能降耗。针对工业领域里这种多目标的问题,已有研究采用多目标控制方法(MOC)来最大限度地提高运行效率且平衡能源消耗。但与其他工业过程不同的是,污水处理过程具有高度不确定性,使用传统的模型预测控制或局部控制方案达不到预期效果。
因此,为了兼顾出水水质和经济运行2方面,需要研究探索更为先进的控制解决方案。而机器学习算法可根据监测结果,全面衡量污水处理系统的运行,预测未来水质变化,监测预警未知异常,从而对污水处理过程进行反馈和微调,达到高效和节能的目的。
2. 机器学习在污水处理系统控制中的应用实例
机器学习在污水处理控制领域的应用多种多样(表1),最初机器学习仅被用作支持决策的辅助系统,帮助工程技术员更好地判断和决策;但随着各类方法的不断优化,已有研究人员开发了自动收集数据的系统,并以特定的方式升级知识库,相关指令直接发送到工程执行终端,完成整个控制过程。
在污水生物处理系统中,溶解氧(DO)是主要控制参数之一,曝气量直接影响污水处理效果和系统运行成本高低。针对这一问题,机器学习方法被研究人员应用于控制曝气系统,实现节能降耗的目标。意大利摩德纳市市政污水处理厂和新加坡某污水处理工厂利用基于神经网络的模型控制器预测主要工艺变量,调整适当曝气量以实现高效和经济的运行效果;也有研究人员利用深度学习中的马尔科夫决策过程(MDP)来寻求污水厂的最佳曝气点,通过不断调整曝气点位置以达到更好的曝气效果。除了控制DO,利用机器学习外,还可以调整污水处理工艺中的其他参数(如氧化还原电位和pH值等)以寻求更好的处理效果。
ANN和GA是污水处理系统控制中使用最多的2种机器学习方法,这2种算法自适应能力强,处理动态问题效果好,因而被广泛应用。如在某大型城市污水处理厂,基于ANN运行的软传感器成为工厂操作员识别污水状态的重要工具,可协助技术人员及时调整污水设施的运行状态。此外,这2类算法近年来也发展了许多改进模型,主要应用案例包括:使用BSM1模型模拟自组织径向基函数(RBF)神经网络模型预测并控制DO浓度;利用比例-积分-微分(PID)神经网络对氨氮浓度和硝态氮浓度进行解耦控制;在新加坡某污水厂实例中,自学习前反馈算法被用于替代传统的PID控制方法,实现了负荷预测,通过系统反馈持续微调曝气量达到减少能耗的目的。此外,近年来研究人员还开发了许多新的机器学习方法应用方式,如使用GA算法改进人工神经网络模型,将基于GA算法优化的神经网络用于活性污泥过程模拟模型进行最优控制,其中包括控制曝气、调整泵和降低处置成本等内容,极大地优化了污水处理厂运行过程中的无必要消耗和违规操作产生次数;利用Q学习算法,将不同的HRT作为环境中的变量,出水COD和磷浓度作为环境变量所带来的收益(出水浓度低即收益高,出水浓度高即收益低)来构建Q表格,寻求能够取得最大收益的环境变量,达到控制SBR中的HRT优化除磷流程的目的;基于机器学习的软传感器预测不可观测的天气情况,根据天气情况调整污水处理系统进水状态,以达到优化污水处理控制系统的目的。
05、其他机器学习方法应用
机器学习方法不需要了解完整的过程机理,仅依靠输入数据集即可得到准确性较高的输出结果,因此在污水处理中被广泛应用。除了上述方面之外,还可用于寻找合适的水处理材料、培养特定污水所需的微生物、建立污水厂能源成本模型、分析污水处理中的关键影响因素和探索更合适的水处理工艺方法等。
06、机器学习方法应用在污水处理系统中存在的问题
尽管机器学习在污水处理领域中应用越来越广泛,且能在不同的情况下有效保障污水处理系统的正常运行,实现节能降耗,但是仍然有问题需要解决。
1)机器学习模型拥有黑盒性质,其自身的可访问性和可解释性差,可能在一定程度上影响系统的稳定性。
2)在污水处理系统中,许多参数采用目前的传感器和其他硬件设备无法获取,如技术特征、环境条件、气象条件、社会状况、工艺设计方向等。这些参数是控制过程中不可缺少的部分,但由于其难以量化和评估,机器学习无法将其纳入学习和训练的范畴。
3)在预测预警及故障诊断方面,机器学习中经常存在数据不平衡问题,即系统中采集到的绝大部分数据都是正常样本,收集到的故障、异常样本数量极小,因此两者间差距较大,而经典分类识别技术要求各类样本分类尽可能均等,这使得机器学习方法的应用具有一定的局限性。在系统控制方面,相比于使用传统数学模型或传统PID控制模型,机器学习模型虽然有着更高的准确性,但其非常依赖历史数据,需要有大量的背景值作为参考,一旦发生剧烈水质变化,建立在大量历史数据基础上的模型可靠性将会下降,无法应对极端条件发生变化的情况,而污水处理中大幅度的水质水量波动较为常见,因此依赖机器学习进行预警、决策及控制无法完全代替传统系统。
07、结束语
目前机器学习在污水处理领域的应用十分广泛,涉及监测、预测、预警、故障诊断和智能控制等多个技术环节,有着极其广阔的发展前景。然而由于机器学习自身特点,其目前应用还存在局限性。以下4方面的问题在未来的相关研究和应用中值得关注。
1)污水系统十分复杂,涉及多种物理、化学、生物反应,且仍然有许多未提取的信息可被利用,如污染物种类、毒性、微生物群落结构和功能等,因此需要开发新的检测方法,完善机器学习的数据系统,为机器学习方法提供更高维度、更具价值和更有表征性的数据。
2)在具体的机器学习模型应用方面,单一的机器模型由于其自身固有的缺点和问题,不能很好地适应污水处理问题,因此多个模型联合使用或采用混合模型来处理污水问题逐渐成为主流趋势。
3)由于机器学习本身拥有黑盒性质,可解释性和可访问性较差,同时机器学习无法应对极端情况,因此开展基础研究,阐明机器学习算法的基本原理并提高其实用性具有重要意义。
4)污水处理领域的科研人员和工程技术人员缺少对机器学习算法和相关理论方面的了解,需开展多学科交叉研究,开发更适合污水处理系统的机器学习方法。
引用格式:芮栋妮,马燕燕,叶林.机器学习方法在污水处理系统中的应用[J].环境工程,2022,40(6):145-153.