基于模型驱动的供水自适应调度应用
01、技术路线
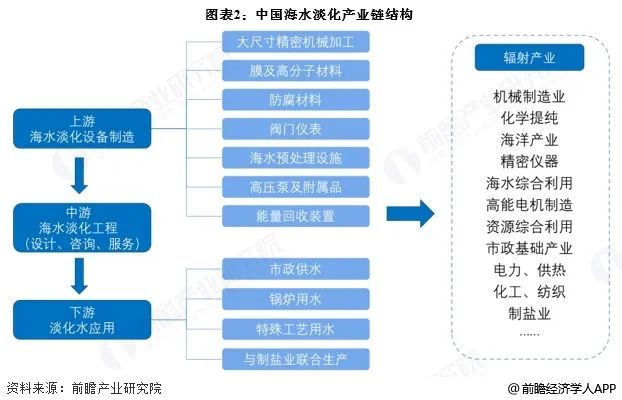
自适应调度依赖厂站网数据在线采集和水力模型引擎服务构建在线实时水力模型系统,并基于水量预测、在线水力计算、智能搜索算法技术开发供水自适应调度模块,以管网稳定运行、厂站安全可控、千吨水能耗优化为目标,优选最合适的调度方案,并与厂站控制系统对接,实现厂网供需水量平衡,达到自适应调度管理的目标。
自适应具体优化调度思路:优化调度一般分为两级优化,一级优化调度即在确保管网运行稳定的情况下,确定厂站最佳的出水压力、流量;二级优化调度即根据一级优化的结果,再进行厂站开泵组合的优化。总体目标是在满足用户需求的基础上,提高机泵运行效率,降低能耗。因此优化对象主要为:一级调度-厂站出水流量、压力的分配;二级调度-厂站机组的开停搭配。
02、实施方法
自适应调度实施方法分为5个步骤(见图1):
(1)水力模型建设:基于管网GIS、厂站管网SCADA压力和流量、在线水表水量、抄表水量等基础数据,构建管网拓扑结构、管网水量平衡关系,结合水力学原理,模拟管网运行状态,通过实测值与模拟值的误差分析、校核迭代,实现管网运行状态等效,从而建立高精度管网水力模型。
(2)水量预测模型建设:根据城市供水运行工况,结合历史水量变化规律、节假日、气象等因素,利用预测算法,建立城市水量预测算法模型。
(3)多工况聚类分析:根据历史运行数据,结合人工经验,提取供水生产运行过程中的工况特征,进行聚类分析,提取调度目标、约束条件。同时对搜索方案进行聚类分析,优化搜索效率。
(4)数学模型建立:根据多工况的调度目标、约束条件,结合管网模型,建立优化调度的数学模型。
(5)方案搜索:系统基于优化调度的数学模型,结合模型规模和计算效率要求,文中采用遗传模拟退火搜索算法,根据SCADA监测信息,自适应校准微观模型或算法参数,生成优化的调度方案。

图1 技术路线
综上所述:自适应调度通过水量预测确定管网需水量,采用遗传模拟退火搜索算法生成调度方案,利用水力模型模拟调度结果,并对工况聚类分析提高计算效率,确定调度目标以此建立数学模型评估调度方案及调度结果,最终实现调度方案的优选。
03、调度应用实例
本次研究以深圳市宝安区FY公司为例,基于在线水力模型构建自适应调度场景。该区域管线长度721 km,模型节点数5.3万个,管道数5.3万根,日供水量约20万m³/d,服务面积41.4 km²,在线压力点56 个,压力监测点密度1.35 个/km²,在线水表率98%。区域内两座水厂,10 台水泵,其中3 台调速泵,7台定速泵。水厂间地势差异很大,FH水厂地面高程较LX水厂高10 m,日常调度以人工经验调度模式,总结调度规律形成分时段压力调控表,水厂根据压力调控表调节机泵状态,满足基本管网需求。当前人工调度模式无法适应管网多变的运行工况,对于管网改造、应急调度等无法准确评估厂站调节后管网运行状态。自适应调度可有效解决人工调度的缺陷,实现真正的自动化调度。
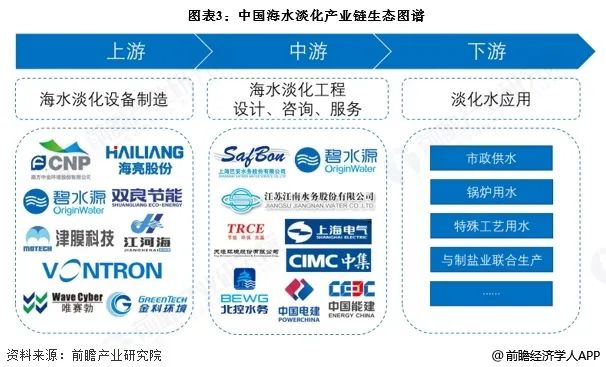
3.1 水力模型建立
FY片区水力模型建设分为两部分:管网模型、泵房模型,目的是适配方案寻优中的二级调度的思路(见图2)。

图2 管网水力模型
管网模型通过收集GIS拓扑资料、水厂出水流量与压力、管网用户水量、管网边界流量、管网SCADA压力等数据建立模型,并校核迭代。模型校核是基础模型建立过程中最为关键的步骤,模型校核的思路就是通过调整模型对象的参数(管道摩阻系数、阀门开度、节点用水量、拓扑连接关系等),使得模型计算结果与实测压力流量的误差在精度允许的范围内。精度校核有关键两点,一是确保管网基本属性、拓扑结构、实测压力流量等数据准确可靠,能代表全管网真实的运行状态;二是在满足能量方程和连续性方程的前提下完善模型、调整参数、反复计算,直至完成高精度模型建设。基础模型建立完成后,计划按季度步长定期校核水力模型精度,选取当次季度中连续一周的高用水量来更新水力模型精度。在本案例中,最新一次的校核时间是2023年6月,FY片区模型的校核结果为:精度满足100%测点压力误差在2 m H2O以内,100%流量误差在管段实际流量的5%以内,关键供水路径测点压力精度在1 m H2O以内。
其中,根据SCADA压力点数据质量分析,压力监测点56 个,参与校验的监测点47个,其中9 个监测点数据无效,精度如表1、表2所示。
表1 压力精度统计

表2 流量精度统计

泵房模型通过收集泵房拓扑结构、水泵特性参数与特性曲线、泵房运行参数(包括:前池水位、水泵状态或频率、出厂压力、出厂流量)等建立模型,并校验迭代,完成高精度泵房模型。两座水厂出厂压力校核精度均在0.5 m H2O以内。
3.2 水量预测模型
管网调度的外部驱动来自用户需求量的变化,因此精准的水量预测是自适应调度的先决条件。城市日用水量一般随时间序列变化,趋势相对稳定。本次研究水量预测采用移动平均整合自回归(ARIMA)、指数平滑等多种算法相结合,每日水量预测的总量误差控制在±3%以内(见图3)。

图3 水量预测
3.3 工况聚类分析
调度工况分析是优化调度的基础,从历史工况中选取调度预判、执行、反馈过程的特征参数,包括:水厂产能、前池水位、水厂机泵状态、水泵功率、出厂压力、出厂流量、管网主控点压力等。对历史工况样本进行聚类分析,采用K-means(K均值)聚类算法,提取相似工况,水力计算时相似工况只需进行一次计算分析,并在算法收敛过程中逐步缩减聚类范围,在保证计算精度的前提下,提升算法运行效率。
3.4 目标函数建立
自适应优化调度分为两级优化,一级优化是在满足管网用水需求与管网稳定运行的情况下,确定厂站最佳的出水压力与出水流量;二级优化是基于一级优化的结果,进行厂站开泵组合的优化。目标是在满足管网用水需求与生产安全的前提下,提高机泵运行效率,降低能耗。
基于以上优化调度的内容,分析管网主控点压力、管网需水量,机泵状态、转速、功率、效率、出口压力、流量等参数,建立目标函数。
目标函数的组成,主要考虑安全性原则及水泵能耗,安全性原则通过损失函数进行表达,水泵能耗通过水泵组合方案的实际功率计算。数学模型概括见式(1):

式中 F——调度系统运行优化函数;
Ln(t)——第n种约束第t时间段的损失函数;
Pi(t)——第i#泵第t时间段水泵功率。
Ln(t)约束条件包括:管网水力平衡见式(2),管网水量供需平衡见式(3),管网监测点、厂站出口压力约束见式(4),厂站水量约束见式(5),水泵运行效率约束见式(6),水泵运行约束见式(7)。

式中Q——管网流量;
P——管网压力;
ηi——第i#泵水泵运行效率;
ni——第i#泵转速;
∑Qj——总供水量;
∑DK——总需水量;
j——测点编号或厂站编号;
Hj min,Hj max——水压约束的下上限;
Qj min,Qj max——水量约束的下上限;
ηj min,ηj max——水泵效率下上限;
nj min,nj max——调速泵转速下上限。
3.5 方案搜索寻优
自适应调度采用遗传模拟退火算法进行方案搜索,将遗传算法和模拟退火算法结合后,可有效改善搜索效果。在供水管网中,遗传模拟退火算法计算精度可达0.001 m以内,SCADA测点测量精度一般为0.1 m以上,因此算法计算结果精度已经远大于测压点的测量精度。遗传算法和模拟退火算法可以有多种结合方式,如串行式遗传模拟退火算法、镶嵌式遗传模拟退火算法。本次研究选择计算效率更高的镶嵌式遗传模拟退火算法。
综上所述,本次研究采用遗传模拟退火搜索算法,通过能耗优化调度的数学模型构造目标函数和约束条件,对相似工况聚类以降低运算量,结合计算机多核并行及分布式运算的特性,实现了能耗最优调度方案的快速搜索。搜索算法与水力计算相结合,开发自适应调度软件,系统根据水量预测、厂站管网监控,实时感知管网供需变化,系统自动计算生成能耗优化调度方案,方案计算速度小于40 s,自适应方案与厂站控制系统对接,自动执行方案内容,响应速度优于30 s,实现智能优化调度。
3.6 应用成效
自适应调度方案运行(见图4),可有效优化管网供水格局,在不同时段将能耗低的厂站提高供水量,能耗高的站点降低供水量,实时计算两者平衡关系,在满足管网需求的情况下,降低整体能耗。自适应调度实际运行取得了显著成效,具体包括:优化管网供水、优化出厂压力、管网运行稳定、节能降耗。

图4 自适应的调度
3.6.1 供水配比优化
人工调度时平峰段两座水厂供水能力充足,有足够的调节空间,人工根据经验一般两座水厂供水比例约5∶5,供水范围见图5。通过自适应调度可实现两座水厂最优供水比例约4∶6,供水范围见图6。

图5 人工调度(5∶5)

图6 自适应调度(4∶6)
3.6.2 出厂压力优化
水厂出厂压力变化显著,自适应调度自动计算结果:降低能耗高的水厂扬程,适当提升能耗低的水厂扬程。LX水厂整体压力下降约1~1.5 m H2O,水厂低峰段压力上升约1 m H2O,高峰段压力上升约0.5 m。从另一方面考虑,LX供水片区地势整体偏低,管网自由压力偏高,该区域适当降压供水对管网用户无明显影响。FH供水片区整体地势偏高,管网自由压力偏低(见图7),该区域适当提压供水,更加有利于低压区用户的用水。因此,通过水厂出厂压力优化可实时有效平衡管网供水。

图7 水厂出厂压力
3.6.3 管网压力平稳
在满足管网用水需求的基础上,适当调整局部管网压力,管网压力控制管网运行更加平稳,主控点压力变化降低,人工经验调度全天主控点压力变化可达2.5 m H2O,自适应调度下压力变化为1.7 m H2O(见图8)。同时高低峰时段压力波动降低,可有效降低管网爆管风险。

图8 管网主控点压力
3.6.4 能耗优化
自适应调度执行后能耗显著优化。一方面通过精准控制管网压力,实现相似工况下水厂开泵晚、关泵早;另一方面3.6.2中出厂压力的调节,降低高能耗的LX水厂的出厂压力,适当提高低能耗的FH水厂的出厂压力,两者均可有效降低能耗。目前自适应运行后FY公司配水电耗由123.77 kW·h/km³下降到120.1 kW·h/km³,能耗整体可下降约3%。
04、结语
文中通过管网水力模型、水量预测模型,结合工况聚类分析,建立自适应调度的数学函数,并采用基于工况聚类的多核并行自适应遗传模拟退火搜索算法,系统自动生成优化调度方案,与厂站控制系统对接,自动下发指令,实现供水系统的自适应调度。以深圳市宝安区FY公司为例,根据实际生产情况,系统实时计算调度方案,在满足管网供需平衡的基础上实现能耗优化。实践应用结论如下:
水力模型和水量预测是自适应调度的基础,自适应调度关键输水路径上压力点校验误差小于1 m H2O,水量预测24 小时供水量误差在3%左右。
自适应调度采用遗传模拟退火算法,结合工况聚类分析,根据供水调度业务场景建立数学函数,应用计算机多核并行及分布式运算的特性,实现了最优调度方案的快速搜索。
FY区域自适应运行,调度方案生成时间约40 s,调度指令执行反馈时间约30 s,区域管网压力平稳,整体配电能耗下降约3%,提升调度效率,长期运行调度岗位至少可减1 人,实现供水调度的提质增效。此方法具有较高的应用价值,建议在供水行业进一步推广应用。